This site may contain outdated or incomplete information.
Fluentd Self-assessment
This assessment was created by community members as part of the Security Pals process, and is currently pending changes from the maintainer team.
Co-authored-by: Nihal Rahman nr2320@nyu.edu Jeffrey Wong jw4186@nyu.edu Garvin Huang gh2222@nyu.edu Jin Zhou jz3928@nyu.edu
Table of contents
Metadata
| Assessment Stage | Incomplete |
| Software | https://github.com/fluent/fluentd |
| Security Provider | No |
| Languages | Ruby, HTML |
| SBOM | Fluentd does not currently generate an SBOM on release. |
Security links
| Doc | url |
|---|---|
| Security file | https://github.com/fluent/fluentd/blob/master/SECURITY.md |
| Default and optional configs | https://github.com/fluent/fluentd/blob/master/fluent.conf |
Overview
Fluentd is an open source data collector to unify data collection and consumption for a better use and understanding of data. It tries to structure data as JSON as much as possible to unify all facets of processing log data: collecting, filtering, buffering, and outputting logs across multiple sources and destinations. This is known as a Unified Logging Layer.
Background
Fluentd decouples data sources from backend systems by providing a unified logging layer in between. This layer allows developers and data analysts to utilize many types of logs as they are generated. The downstream data processing is much easier with JSON, since it has enough structure to be accessible while retaining flexible schemas. Just as importantly, it mitigates the risk of “bad data” slowing down and misinforming your organization. A unified logging layer allows for better use of data and quicker iteration on software. 2,000+ data-driven companies rely on Fluentd to differentiate their products and services through a better use and understanding of their log data.
Fluentd is written in a combination of C language and Ruby. The vanilla instance runs on 30-40MB of memory and can process 13,000 events/second/core. Fluentd supports memory- and file-based buffering to prevent inter-node data loss. Fluentd also supports robust failover and can be set up for high availability. Fluentd is Apache 2.0 Licensed, fully open source software.
Actors
A data collector is an application that collects the metadata about different systems and delivers it to be analyzed. Fluentd is a data collector that has a decentralized ecosystem that promotes built-in reliability and cross-platform compatibility. One of the biggest challenges in big data collection is the lack of standardization between collection sources. FluentD addresses this challenge using its Unified Logging Layer. Fluentd can retrieve data from multiple external sources and output them to various destinations. The following diagram shows possible sources and destinations for Fluentd:
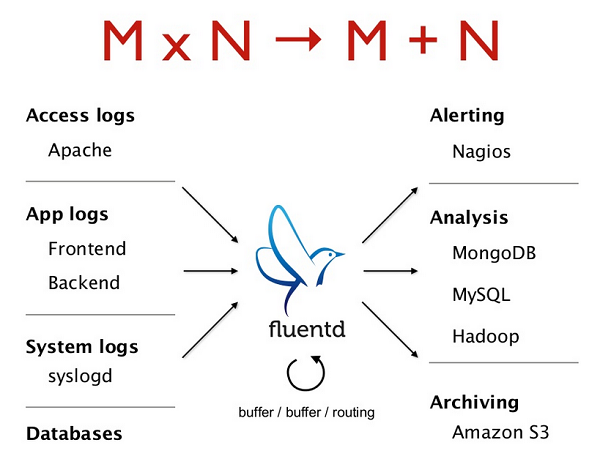
Fluentd is a relatively lightweight program in its vanilla instance, and there are 3 main actors in the architecture of Fluentd:
- Core Configuration: The configuration file sets up rules and parameters for logging events by specifying plugins. The Fluentd core executable initializes that pipeline of plugins, and runs concurrently with the plugins to continually process events.
- Plugins: Fluentd is composed of plugins that perform specific functions. Each plugin is executed independently of the core process and of each other, but exchange data along the pipeline.
- Plugin API: Fluentd has Plugin APIs for third parties to create custom plugins. There are 2 versions for the current v1 and the old v0.12. Fluentd v1 supports both v1 and v0.12 APIs.
Actions
Fluentd log pipelines consist of different types of plugins stitched together to perform specific and customizable data processing operations. Some of these plugins are available in the base package, while others are installed on Fluentd. There are over 500 community plugins for Fluentd that can read data including enterprise staples like Kafka, as well as data heavy backends like Hadoop and MongoDB. Generally speaking, a Fluentd pipeline consists of three stages, input, processing, and output, which are setup by configuring different Fluentd plugins.
There are a total of 9 types of plugins in Fluentd: input, parser, filter, output, formatter, storage, service discovery, buffer, and metrics. The configuration file allows the user to define inputs or listeners and set up common matching rules to route logging event data to specific outputs by specifying and configuring these plugins. Each logging event is processed by the core configuration, which initializes the plugins in the order in which they are specified in the configuration file. The events follow a step-by-step cycle where they are processed in order, from top to bottom, and the plugins send logging data down the pipeline. Fluentd is equipped with a password-based authentication mechanism, which verifies the identity of each client using a shared secret key. For example, the secure_forward plugins for input and output (in_secure_forward and out_secure_forward) accepts and sends messages via SSL with authentication. Fluentd has a flexible plugin system that allows the community to extend its functionality, but any Fluentd plugin can unknowingly break Fluentd completely (and possibly break other plugins) by requiring some incompatible modules.
Goals
Fluentd is an open source data collector, which lets you unify the data collection and consumption for a better use and understanding of data. It does this by structuring the log data as JSON as much as possible. Fluentd tries to structure data as JSON as much as possible: this allows Fluentd to unify all facets of processing log data: collecting, filtering, buffering, and outputting logs across multiple sources and destinations.
Non-goals
- Fluentd doesn’t handle missing data.
- Fluentd recommends capping the max amount of time to wait until attempting a retry connection to the backend.
- Fluentd recommends manually running the application with input in terminal.
- Fluentd recommends checking the configuration settings.
- Fluentd doesn’t make sure the logs are parsed correctly.
- Fluentd recommends using online tools such as Rubular.com and fluentular.
- Fluentd recommends checking existing parsers.
- Fluentd recommends checking the configuration settings.
- Fluentd continously writes with errors if the buffer is full.
- Fluentd recommends checking the flush_interval.
- Fluentd recommends increasing workers and flush_thread_count.
- Fluentd recommends changing buffer type to file.
- Fluentd recommends manually changing buffer size in the parameters.
Self-assessment use
This self-assessment is created by our team to perform an internal analysis of the Fluentd project’s security. It is not intended to provide a security audit of Fluentd, or function as an independent assessment or attestation of Fluentd’s security health.
This document serves to provide Fluentd users with an initial understanding of Fluentd’s security, where to find existing security documentation, Fluentd plans for security, and general overview of Fluentd security practices, both for development of Fluentd as well as security of Fluentd.
This document provides the CNCF TAG-Security with an initial understanding of Fluentd to assist in a joint-assessment, necessary for projects under incubation. Taken together, this document and the joint-assessment serve as a cornerstone for if and when Fluentd seeks graduation and is preparing for a security audit.
Security functions and features
Critical:
- TCP: The input and output plugin that enables Fluentd to accept (Transmission Control Protocol)TCP payload. Including TLS encryption that secures messages and TLS mutual authentication, checking all incoming requests for a client certificate signed by the trusted CA, and blocking all requests that have an invalid client certificate.
- UDP: The input and output plugin that enables Fluentd to accept UDP payload. This enables Fluentd to transmit messages following the User Datagram Protocol(UDP), which is especially essential for time-sensitive transmissions.
- Forward: The input and output plugin that listens to the TCP socket to receive the event stream, which allows event log retrieval from other Fluentd instances. Safely transmitting data between Fluentd instances with the help of TCP.
- Memory: The buffer plugin that uses memory to store buffer chunks. When Fluentd is shut down, buffered logs that cannot be written quickly are deleted to avoid incomplete data written into the memory.
Security Relevant:
- Pre-installation It is recommended to
- Set up an NTP daemon for accurate current timestamp which is essential for product-grade logging services.
- Set up AWS-hosted NTP server for AWS users.
- Increase the Maximum Number of File Descriptors to guarantee sufficient file descriptors for Fluentd.
- Optimize the Network Kernal Parameters to secure smooth network connection for Fluentd.
- Use sticky bit symlink/hardlink protection to ensure link security because Fluentd sometimes uses predictable paths for dumping, writing files, and so on.
Logging Fluentd has two logging layers: global and per plugin, combined they grant the ability to track all events that occurred, including security-related ones. This is important for monitoring and analysis, providing observability regarding security issues.
Memory Buffering When the destination Fluentd instance dies, certain logger implementations will use extra memory to hold the incoming logs that would be immediately sent again once Fluentd comes back, ensuring no critical security events and activities discarded that might affect the overall safety.
Project compliance
- The Fluentd project has earned a passing status on the OpenSSF Best Practices Badge , illustrating its dedication to quality and security.
Secure development practices
Development Pipeline
All code is maintained in a public repository on GitHub, and all changes need to be reviewed by the maintainers. See Fluentd workflow for the detailed pipeline for contributors.
- All source code are publicly available on GitHub.
- Manually test the code through
bundle exec rake testbefore PR. - All changes are made to a forked repository under the branch named new-feature.
- Commit the final changes to the original repository through PR.
- All the commits requires to be signed by the contributor under the regulation of Developer Certificate of Origin .
- Once the PR is created, it will be assigned to one or more reviewers.
- Merging automatically occurs after the PR is approved by the reviewer and contributor.
Communication Channels
- Internal Team members communicate through Fluentd Community Slack , GitHub issues , and GitHub discussions .
- Inbound Users can communicate with the team through Fluentd Community Slack , GitHub issues , GitHub discussions , and Stack Overflow .
- Outbound The team communicates with users through the Maillist , and their official Newsletter .
Ecosystem
Fluentd is the default standard to solve Logging in containerized environments, for example, both Docker and Kubernetes have integrated Fluentd. After joining CNCF, Fluentd has formally became a part of a cloud-native stack.
Security issue resolution
- Responsible Disclosures Process.
- Security vulnerabilites are to be reported at https://github.com/fluent/fluentd/security/advisories , as stated in their security policy
- Incident Response.
- Fluentd is trying to follow supply chain security using
DCO
(Supply chain security) - Because Fluentd is built on top of the Ruby Ecosystems, they must also check the licenses of dependent gems.
- Fluentd is trying to follow supply chain security using
DCO
Appendix
Known Issues Over Time
There are no documented vulnerabilities for FluentdCII Best Practices The Fluentd project has adopted the CNCF Code of Conduct, and earned a Core Infrastructure Initiative Best Practices Badge in August 2017
Case Studies. Many companies have adopted Fluentd. List of adopters
Here is one such case study:- LINE- LINE Corporation is known for its messenger app and the various services on its platform,
and is faced with the challenge of collecting, storing and analyzing massive log data everyday.
The corporation originally used a classic Hadoop setup: They used the Scribe log collector to collect everything into Hadoop
and run batch jobs on Hadoop to process the logs. However, there was still room for improvement, which Fluentd provided.
- Fluentd is used as the primary data stream processor against terabytes of data everyday.
- Using Fluentd, LINE developed many custom plugins, allowing for more flexible data processing
- One of LINE’s engineers were able to build a schemaless SQL stream processing engine on top of Fluentd. Full details on LINE case study
- LINE- LINE Corporation is known for its messenger app and the various services on its platform,
and is faced with the challenge of collecting, storing and analyzing massive log data everyday.
The corporation originally used a classic Hadoop setup: They used the Scribe log collector to collect everything into Hadoop
and run batch jobs on Hadoop to process the logs. However, there was still room for improvement, which Fluentd provided.
Related Projects / Vendors
Fluentd is unique in its use of a Unified Logging Layer in order to reduce the complexity of backend data parsing. Related projects:- Fluentd, combined with Elastisearch and Kibana, is a free alternative to Splunk. ( Details )
- Fluentd can be used in conjunction with Norikra to create a SQL-based realtime complex event processing platform. ( Details )
- Fluentd can be used with Amazon Kinesis to aggregate semi-structured logs in real-time ( Details )
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.